
Aus einer Wordcloud regnet es keine Buchstaben. Sie ist aber eine schöne Form, um Worthäufigkeiten in Texten anschaulich darzustellen. Das Online-Tool Wordle beispielsweise liefert wunderschöne Bilder, die sich in Präsentationen oder Flyern sehr schön machen. Der Fantasie sind beider Erstellung keine Grenzen gesetzt. Leider kann man das Online-Tool nur bedingt für das gezielte Suchen nach Informationen in einer großen Textmenge einsetzen. Dafür gibt es andere Lösungen. In diesem Beitrag zeige ich am Beispiel von Tweets mit den Hashtags #wirhabenessatt und #wirmacheneuchsatt, wie aus 3.849 Tweets zwei unterschiedliche Wordclouds werden. Und auch welche Überraschungen sie in sich tragen. Warum zum Beispiel taucht das Keyword „Ostfriesland“ in der #wirmacheneuchsatt Wordcloud auf?
Eine Abfrage der Twitter-Api im Januar hat fast 3.850 Tweets mit den Hashtags „#wirhabenessatt (3.753) und #wirmacheneuchsatt (96) zu Tage gefördert. Damit haben am 16.01.2016 Teilnehmende und Unterstützende zweier Demos in Berlin ihre Tweets versehen. Während die einen forderten, das Ernährungssystem umzubauen, setzten sich die anderen für eine sachlichere Diskussion in Agrarfragen ein. Dazu habe ich im ersten Teil dieser kleinen Serie bereits etwas geschrieben. Im dritten Teil geht es dann um die Analyse von Netzwerken aus Tweets und Retweets.
Eine einfache Text Mining Technik: Wörter zählen
Tausende von Tweets einzeln zu lesen, dafür dürfte den meisten Menschen die Zeit fehlen. Aber deshalb muss man nicht auf die Informationen verzichten, die darin enthalten sind. Mit Hilfe einiger einfacher Text Mining Techniken lassen sich bereits einige ganz gute Aussagen zu Tage fördern. Das Zählen häufig vorkommender Worte, bzw. das Ermitteln der Worthäufigkeit oder Wortfrequenz gehört zu diesen Techniken. Eine beliebte Form, die Wortfrequenzen anschaulich zu präsentieren ist die Wordcloud.
Aufgrund guter Erfahrungen nutze ich für die Erstellung meiner Wordclouds die freie Software R. Sie unterstützt mich auch bei meinen anderen Untersuchungen. Die Software kann auf der R-Projektwebseite kostenlos heruntergeladen werden. Leider ist sie nicht ganz selbsterklärend. Wer aber bereits über Programmierkenntnisse verfügt oder bereit ist, sich welche anzueignen, der sich wird sich schnell damit zurecht finden.
Zusätzlich zum Basis R-Basis-Paket gibt es zahlreiche Ergänzungspakete, die auf spezielle Analyseanforderungen zugeschnitten sind. Für das Text Mining beispielsweise ist das Paket „tm“ von Ingo Feinerer und Kurt Hornik ausgesprochen hilfreich. Auch dieses Paket kann von der R-Seite geladen werden.
Wer sich für das Thema Text Mining näher interessiert, für den ist vielleicht auch der Blogbeitrag „A gentle introduction to text mining using R“ interessant. Der Autor Kailash Awati erklärt dort (auf Englisch), wie man mit R schrittweise Informationen aus Texten herauszieht. Auf diese Erklärungen möchte ich hier verzichten.
Woraus ein Tweet besteht
Bevor man jedoch die Wordcloud erstellt, sind einige Vorbereitungen und Überlegungen notwendig. Dazu sieht man sich den Tweet einmal näher an: Er besteht aus verschiedenen Text-Teilen. Im Beispiel hat der Autor oder die Autorin drei Hashtags benutzt (erkennbar am #). Zudem ist der Twitter-Nutzername des Deutschen Bauernverbands (DBV) erwähnt (erkennbar am @) sowie zwei Links und der Text „Tausende demonstrieren…“ enthalten.
Manchmal kommen auch noch Sonderzeichen oder Emojis (kleine Bilder, die Emotionen oder sonstiges grafisch illustrieren) zum Einsatz. Eine Einschränkung bei meiner Abfrage über die Twitter-API: Twitter liefert keine mit. Je nach Forschungsfrage können aber alle Tweet-Bestandteile eine Rolle spielen.
Weitere Informationen geben an, wie oft der Tweet aufgegriffen und weitergeschickt also retweetet wurde (hier zweimal) und wie oft er favorisiert wurde (hier dreimal) (Stand: 04/2016).
#WirHabenEsSatt“ vs #WirMachenEuchSatt: Tausende demonstrieren in #Berlin https://t.co/Pw28iMmelD @Bauern_Verband pic.twitter.com/9tf1fp0GZ5
— BZ Berlin B.Z. (@bzberlin) 16. Januar 2016
Die Wordcloud für #wirhabenessatt
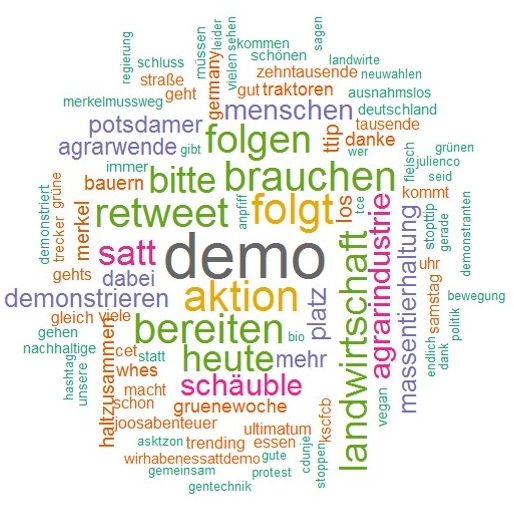
Jetzt zu den Ergebnissen. In die Auswertung sind nur Tweets eingegangen. Tweets, die nicht als Retweet gekennzeichnet sind. So können sehr häufige Retweets die Kerninhalte und –aussagen nicht verzerren. Verblieben sind (1.041) Tweets. Außerdem habe ich für die Auswertung Nutzernamen, Links und die Hashtags entfernt und nur relativ häufige Worte in die Wordcloud einbezogen.
Je größer ein Wort im Verhältnis zu den anderen, desto häufiger haben es die Nutzer und Nutzerinnen von Twitter beim Twittern verwendet. Diejenigen, die über die „Wir haben es satt-Demo“ geschrieben haben, haben die Worte „Demo“ und „Berlin“ am meisten verwendet. Das Wort „Berlin“ musste ich aus Gründen der Übersicht allerdings nachträglich aus der Analyse entfernen.
Unter den Top 30 befinden sich auch Begriffe wie „Landwirtschaft“, „Massentierhaltung“, „Agrarindustrie“ und „Agrarwende“, „TTIP“. Aber auch Politikernamen wie „Schäuble“ und „Merkel“.
Insgesamt beschreiben diese Worte treffend, worum es den Befürwortern einer bäuerlichen Landwirtschaft geht. Das auch Begriffe wie „Schäuble“ und „TTIP“ fallen, deutet darauf hin, dass der Blick der Demonstrierenden und Befürwortenden über reine Landwirtschaftsaspekte hinausgeht. Auch globale Zusammenhänge stehen im Fokus.
Die Wordcloud für #wirmacheneuchsatt

Anders sieht es bei den Tweets zur „Wir machen euch satt“-Aktion aus. Hier bilden lediglich 56 Tweets die Auswertungsgrundlage. Unter den Top Begriffen befinden sich „Berlin“ als Ort der Veranstaltung sowie die Worte „Bauern“, „Verband“, „Deutschland“.
Aber auch Worte wie „Ostfriesland“ und überraschenderweise auch der Begriff „wirhabenessatt“. An diesen Stellen lohnt sich in der Regel ein genauerer Blick. Warum ausgerechnet Ostfriesland?
Und hier die Antwort: Besonders viele Tweets wurden über das Konto der @LHVOstfriesland gesendet. Und die haben zurecht darauf hingewiesen: Auch in Ostfriesland produzieren Bäuerinnen und Bauern Lebensmittel und sorgen dafür, dass Menschen satt werden.
Auch in Ostfriesland 🙂 #wirmacheneuchsatt https://t.co/AAkQyLfaSU
— LHV e.V. (@LHVOstfriesland) 16. Januar 2016
Eins ist mir allerdings auch aufgefallen: Da das Ziel der Veranstaltung war, für einen sachlicheren und ideologiefreien Dialog in Agrarthemen einzutreten, vermisse ich hier einige Stichworte. Nämlich „Dialog“, „Kommunikation“, „miteinander“ oder das Verb „reden“.
Fazit
Zu zählen, wie häufig ein Wort in einem Text vorkommt ist eine einfache Technik des Text-Minings. Mit Unterstützung der Software R ist es auch kein Problem, wenn man ein paar Grundzüge beachtet. Anhand der Worthäufigkeiten lassen sich bereits einige Informationen aus Texten herausziehen, wie hier am Beispiel von Tweets gezeigt.
In Tweets, die ja per Vorgabe auf 140 Zeichen begrenzt sind, sind gerade die häufigen Schlüsselworte Träger von Sinn und Unsinn. Da die Tweets in meiner Analyse ja durch die Hashtags inhaltlich ja bereits weitgehend vorgegeben waren, macht das die Worthäufigkeiten und die Darstellung in einer Wordcloud zu einem geeigneten Mittel.
Die Schlagworte und Schlüsselbegriffe der Tweets mit #wirhabenessatt offenbaren eine größere Themenorientierung als die Tweets mit #wirmacheneuchsatt. Das kann aber auch der größeren Zahl der Tweets geschuldet sein. Die Befürworter und Befürworterinnen eines fairen Agrardialogs müssen gegebenenfalls nochmal über ihre Botschaften nachdenken. Vielleicht sieht im nächsten Jahr die Wordcloud auch bunter aus und neben Ostfriesland stehen noch andere Begriffe.
Dennoch: Wordclouds sind nicht die einzigen Mittel zur visuellen Darstellung von Tweet-Inhalten. Im dritten Teil dieser kleinen Serie geht es um die Darstellung sozialer Netzwerke, die aus Tweets und Retweets geknüpft sind. Im ersten Teil geht es um die Hashtags.